-
Kafka를 이용한 채팅서버 개발Spring 2024. 3. 15. 23:34
서론
Spring Boot를 이용하여 채팅서버를 개발해보았다. 기본적으로 채팅같은 경우에, 실시간성이 중요하고 지속적으로 통신을 진행해야 하기 때문에 socket 통신을 기반으로 제작하였다. 만약 채팅방이 하나만 있는 경우에는 하나의 소켓풀만 관리를 하여, 유저가 채팅을 날리면 해당 소켓풀에 존재하는 모든 인원들에게 메세지를 보내주면 된다.
만약 채팅방이 여러개라면 ?
여러개의 소켓풀을 개발자가 직접관리하고, 새롭게 들어온 소켓에 대해서 기존의 소켓풀에 할당하거나 새로운 소켓풀을 일일히 만들어야 한다는 단점이 존재한다.
이러한 단점을 극복하기 위해서 STOMP 프로토콜을 사용하였다.

해당 프로토콜의 동작원리를 위와 같다.
Publisher가 특정 토픽에 메세지를 보내면, 해당 토픽을 구독하고 있는 subscriber에게만 메세지를 간편하게 보낼 수 있다는 장점을 가지고 있다.
만약 서버가 여러대라면 ?
STOMP는 하나의 서버 내에서만 유효하다. 다시 말해서, 하나의 서버 내에서 특정 토픽에 대한 구독과 발행이 유효하기 때문에 서버가 많아 진다면 각 서버내에 존재하는 소켓들의 정보에 대한 동기화가 필요하다는 것이다.
이를 극복하기 위해 Kafka를 도입하였다.
본론
채팅서버에서의 kafka의 작동원리는 다음과 같다.
1. 사용자가 구독을 한 특정 topic으로 메세지를 보낸다.
2. 서버는 해당 메세지를 받고, 해당 메세지를 다시 Kafka에게 전달한다
3. 각 서버들은 Kafka Consumer들을 가지고 있기 때문에, 특정 topic에 대한 요청이 왔을때 이를 감지하고 다시 해당 토픽을 구독하고 있던 구독자들에게 메세지를 전달해준다.
Kafka의 도입목적
해당 내용만 본다면 Kafka의 도입목적은 데이터 동기화 이다. 하지만 Kafka를 단순히 Partition이 하나인 Messsage Queue로서, 데이터동기화 목적으로만 사용한다면 그건 Kafka를 적절하게 활용하는 방법이 아니라고 생각하였다.
왜냐하면 Kafka의 가장 큰 특징인 분산처리를 적용하지 않았기 때문이다.
이를 개선하기 위해 Partition을 3개로 나누어 보았다.
파티션을 나눴을때의 고려해야할 점
1. Kafka의 가장 큰 특징 중 하나는 파티션 내에서는 순서보장이 가능하지만, 파티션 사이에서의 순서보장이 되지 않는다는 것이다.
2. 기본적으로 데이터가 Kafka에 전송되면, RR방식을 통해서 Partition에 랜덤하게 들어간다,
이 두가지 특징을 조합해 본다면, 하나의 채팅방에서의 대화들도 다른 Partition에 들어가서 순서가 보장되지 않을수도 있다. 이를 극복하기 위해서는 특정 파티션에는 특정 채팅방 메세지만 할당되도록 만들어야 한다.
이를 해결하기 위해 Parition Key를 도입하였다.
@Service @Slf4j public class KafkaProducer { private KafkaTemplate<String, String> kafkaTemplate; @Autowired private ObjectMapper objectMapper; @Autowired public KafkaProducer(KafkaTemplate<String, String> kafkaTemplate) { this.kafkaTemplate = kafkaTemplate; } public void send(String topic, ChatDto chatDto) { int roomId = chatDto.getRoomId(); try { String jsonMessage = objectMapper.writeValueAsString(chatDto); kafkaTemplate.send(topic,roomId%3,null, jsonMessage); } catch(Exception e){ e.printStackTrace(); } } }Parition이 3개인 경우
채딩방의 아이디를 3으로 나눈 값들을 해당 Parition에 수동으로 전달해준다.
그렇게 된다면
나머지가 0 -> Partition 0
나머지가 1 -> Partition 1
나머지가 2 -> Partition 2
에 할당이 되며 각 채팅방의 내용들은 순서를 유지할 수 있게 된다.
Kafka를 사용할 때 가장 중요한 점 중 하나는, Partition 수만큼 Consumer가 존재해야지 분산처리를 가장 효과적으로 할 수 있다는 것이다.
따라서 아래와 같은 방식으로 Consumer를 구성하였다.
@Service public class KafkaConsumer { @Autowired private SimpMessagingTemplate simpMessagingTemplate; @Autowired private ObjectMapper objectMapper; @KafkaListener(groupId = "chat-group", topicPartitions = @TopicPartition(topic = "chat", partitions = {"0"})) public void listen1(String kafkaMessage) { try { // JSON 문자열을 ChatDto 객체로 파싱 ChatDto chatDto = objectMapper.readValue(kafkaMessage, ChatDto.class); int roomId = chatDto.getRoomId(); simpMessagingTemplate.convertAndSend("/sub/chatroom/" + roomId, chatDto); } catch (Exception e) { e.printStackTrace(); } System.out.println("Partition 0" + kafkaMessage); } @KafkaListener(groupId = "chat-group", topicPartitions = @TopicPartition(topic = "chat", partitions = {"1"})) public void listen2(String kafkaMessage) { try { // JSON 문자열을 ChatDto 객체로 파싱 ChatDto chatDto = objectMapper.readValue(kafkaMessage, ChatDto.class); int roomId = chatDto.getRoomId(); simpMessagingTemplate.convertAndSend("/sub/chatroom/" + roomId, chatDto); } catch (Exception e) { e.printStackTrace(); } System.out.println("Partition 1: "+kafkaMessage); } @KafkaListener(groupId = "chat-group", topicPartitions = @TopicPartition(topic = "chat", partitions = {"2"})) public void listen3(String kafkaMessage) { try { // JSON 문자열을 ChatDto 객체로 파싱 ChatDto chatDto = objectMapper.readValue(kafkaMessage, ChatDto.class); int roomId = chatDto.getRoomId(); simpMessagingTemplate.convertAndSend("/sub/chatroom/" + roomId, chatDto); } catch (Exception e) { e.printStackTrace(); } System.out.println("Partition 2: "+kafkaMessage); } }이를 통해 아래의 결과를 얻을 수 있었고, Kafka의 장점을 극대화하면서 메세지의 순서보장을 가능하게 만들었다.
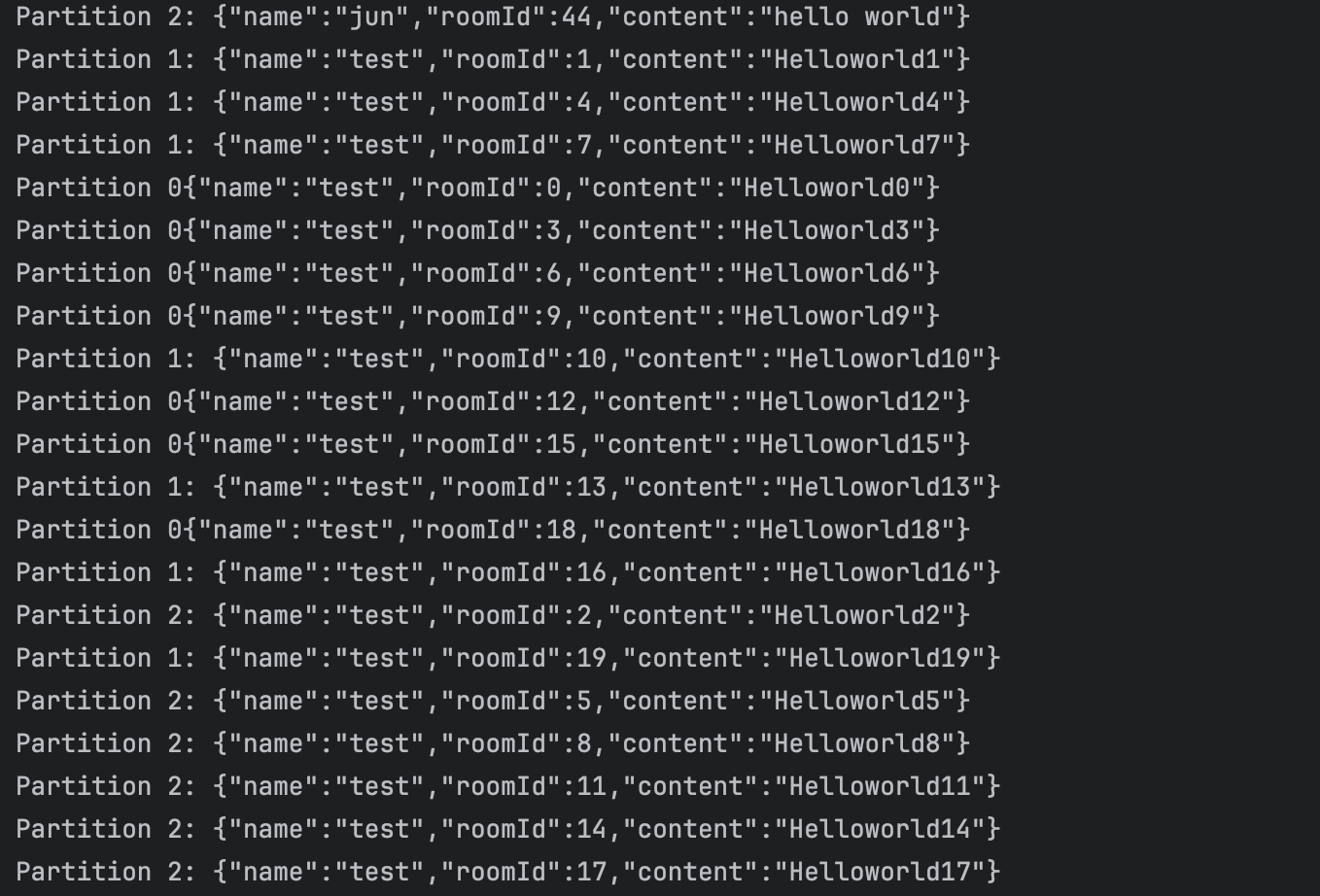
해당 결과를 간략하게 설명하자면, roomId를 3으로 나눈 나머지 값의 파티션에 메세지가 할당된 것을 확인하여 분산처리가 성공적으로 이루어졌음을 알 수 있다.
결론
1. Scale out + 데이터동기화를 목적으로 Kafka를 도입하였지만, RR방식으로 여러 Partition에 데이터가 전달되기 때문에 메세지 순서보장이 어렵다.
2. 이를 극복하기 위해 Partition Key를 사용하여 특정 채팅방이 특정 파티션에만 종속되도록 만들었다.
궁금한점
1. Kafka Consumer에 Timeout이 발생하였을 경우에 consumer group 안에서의 Rebalancing이 일어난다고 한다. 해당 일이 일어났을때 각 Consumer들이 offset을 올바르게 트래킹하지 못한다면 일부 메세지가 유실되는 일들이 일어날 것이다. 이를 어떻게 극복할 수 있을까?
'Spring' 카테고리의 다른 글
AssertJ 오픈소스 컨트리뷰트 하기 (0) 2024.08.05 지연로딩 , 즉시로딩 JPA 최적화 (1) 2024.07.01 Spring - gRPC 적용 성능 최적화 (0) 2024.05.01 서버 성능개선 - sql batchupdate (0) 2024.01.11
